Airflow Review
Airflow Review
Airflow 기본 소개
Apache Airflow란 Workflow 스케줄링, 모니터링 플랫폼으로서 현 시대에서 배치 프로세싱을 위해 자주 쓰이는 강력한 툴 중 하나이다. 스케줄링으로 기존 Crontab을 사용하는 방식보다 실패복구, 모니터링 (웹 대시보드 존재), 의존성 관리, 확장성, 배포에서 훨씬 쉽다. 또한 Airflow는 python으로 쉬운 프로그램이 가능하다.
Workflow는 의존성 (dependency)로 연결된 task들의 집합이라 보면 된다. 이러한 Workflow는 DAG (Directed Acylic Graph) 형태를 가지며 이를 통해 의존성 관리를 한다. Airflow는 operator를 통해서 이러한 task들을 정의할 수 있는데, 크게 연산을 수행하는 action operator, 데이터를 옮기는 transfer operator, 그리고 트리거를 기다리는 sensor operator의 세가지 operator 종류가 있다. 이러한 operator를 실행시키면 task가 된다.
Airflow 구조
Airflow의 구조는 다음 그림과 같이 볼 수 있다.

다음과 같이 Worker, Scheduler, Metastore, Webserver, Executor로 나눌 수 있다.
- Scheduler
스케줄러는 계획된 workflow를 trigger하고 task를 executor에게 제출한다. - Metastore
메타 스토어는 DAG에 대한 정보를 담고 있어서 webserver와 scheduler가 이를 읽어온다. Executor는 구동하고 상태를 Metastore에 업데이트한다. - Webserver
UI로 유저가 DAG와 task를 debug, inspect, trigger하게 해준다. - Executor
Task가 어떻게 실행될지를 정의하는 곳이다. Worker를 사용해 구동한다. Queue가 있어서 순서대로 가져간다.
이를 Kubernetes 환경으로 옮기면 (multi-cluster) 다음과 같다.
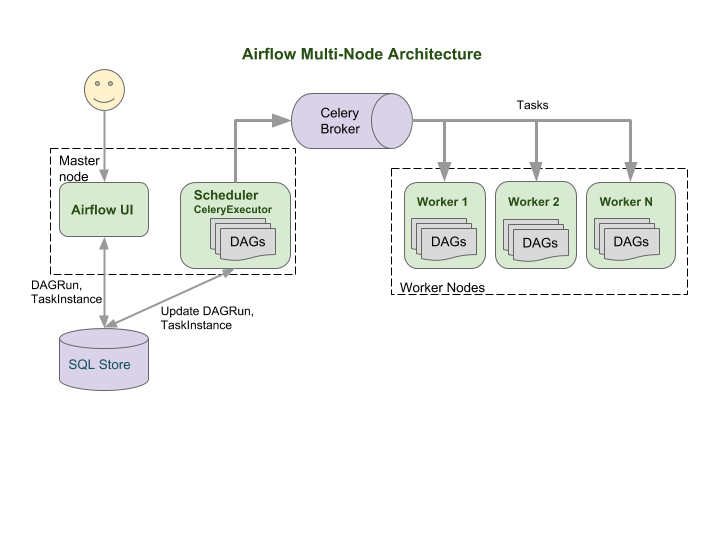
크게 차이가 나지는 않다. Airflow UI와 Scheduler가 SQL Store의 메타 데이터 정보를 읽어 오고, 이러한 데이터를 Celery Executor를 통해서 Celery Broker에 담게 되는데, 그러면 worker들이 나눠서 가져가게 된다. 완료가 되면 상태를 업데이트하고, UI와 스케줄러가 읽어와서 완료된걸 확인하게 된다.
Executor를 Celery Executor를 사용하지 않고 Kubernetes Executor (or Kubernetes Celery Executor)를 사용할 수 도 있다. 이것의 장점은 태스크 단위로 팟을 띄우게 되서 각 태스크마다 다른 환경에서 커스터마이징할 수 있다. DAG를 관리하는 팀이 여러 팀이라면 좋을 수 있겠지만 리소스를 많이 잡아먹긴 한다.
따라서, 동작을 정리하자면…
- DAG를 만든다. DAG는 task로 구성되어 있다.
- 스케줄러와 웹서버는 DAG 파일을 읽고 파싱한다.
- 스케줄러는 메타스토어에 DagRun Object (DAG의 인스턴스)를 생성한다. 해당 Object에는 Task가 포함되어 있다. 이러한 DagRun의 상태를 Running으로 바꾸게 된다.
- Task가 준비가 되면 Task Instance를 생성된다.
- Scheduler는 trigger가 되면 Task Instance를 Executor에게 보낸다.
- Executor는 Worker에게 전달해 Task Instance를 구동을 하고, Metastore에 Task Instance의 상태를 업데이트 한다.
- Scheduler는 DagRun을 통해 완료를 확인하고 잘 완료되었다면 Completed로 상태를 바꾼다.
- Server는 DagRun의 상태를 받아 사용자에게 보여준다.
Airflow 설치하기/간단 로컬 셋업
pip install apache-airflow
이 커맨드를 통해서 설치할 수 있다. 이후 airflow라고 치면 airflow cli가 생성이 된다. 이렇게 하는 방법보다는 docker를 활용해 airflow를 셋업하거나 airflow-on-k8s-operator를 쓰는게 편하긴 하다.
Git-Sync를 통해서 k8s환경에서 dag파일들을 github에서 관리할 수 있다.
Airflow CLI를 사용해서 local에서 실험하고 싶다면, airflow db init을 통해 database를 initializa할 수 있고, airflow webserver -p 8080을 쳐서 Web UI를 띄울 수 있다. 그리고 airflow scheduler를 통해 스케줄러를 띄워줘야 한다. 먼저 유저를 생성해줘야하는데, airflow users create ***이렇게 만들어줄 수 있다. 사실 개인적으로 airflow CLI는 task를 test할때 가장 유용하다 생각하는데, airflow tasks test hourly_etl load_some_data 2022-01-01 이런식으로 dag를 task를 테스트 해볼 수 있다. 또한 airflow dag -list를 통해 dags 리스트를 cli에서 볼 수 있다.
Airflow DAG파일 써보기
default_args = {
'owner': 'yongchana',
'depends_on_past': False,
'start_date': datetime(2022, 01, 01, tzinfo=UTC),
'retries': 0,
}
dag = DAG(
dag_id=DAG_ID,
default_args=default_args,
description='hello',
schedule_interval='@daily',
catchup=False,
doc_md=__doc__,
)
alphabets = ["a", "b", "c", "d", "e"]
tasks = {}
for alphabet in alphabets:
task = PythonOperator(
task_id=f"print_{alphabet}",
python_callable=print_alphabet,
op_kwargs={"alphabet": alphabet},
dag=dag,
)
tasks[alphabet] = task
tasks["a"] >> tasks["b"] >> tasks["c"] >> tasks["d"] >> tasks["e"]
오늘의 집 코드 + 개인 코드를 참고하였다. dag 부분을 먼저 보자. dag 부분에선 DAG로 먼저 정의하고, default_args로 start_date 등을 정해줄 수 있고 dag정의 할때 스케줄 인터벌과 설명을 넣을 수 있다.
depends_on_past를 True라 하면 과거에 실패하면 다시 구동하지않는다.
catchup = False라 하면 start_date와 달라도 처음부터 구동하지않는다.
task 부분을 보자.
Operator는 여러가지가 있는데, 자주 쓰는건 PythonOperator, HttpOperator, BashOperator, SparkKubernetesOperator, SparkSubmitOperator 등이 있다.
Operator를 직접 정의해서 사용할 수 있다. class로 사용하고 Base operator를 기반으로 쓸수 있다.
이 Python Operator에서 보듯 task_id를 지정해줄 수 있고, jinja template이 가능하다.
또한, python_callable로 함수를 호출 할 수 있고, op_kwargs를 통해 파라미터를 전달 할 수 있다.
task내 dependency를 정의해주기 위해 bitshift operator 인 »나 «를 써줄 수 있다. A » B라 하면 A가 B의 upstream이다.
DAG내에서 Operator를 정의하면 bitshift operator가 없어도 자동으로 task가 생성된다.
Airflow 이모저모?
- DAG ID는 고유해야 한다.
- Airflow 웹에서 Connection/Variable 로 생성해서 가져올 수 있다.
- Variable.get(‘NAME’)으로 Variable 받아올 수 있다.
- BaseHook.get_connection(conn_id = ‘NAME’)으로 Connection을 받아올 수 있다. Hook로 다른 외부 플랫폼, 데이터베이스와 연결 가능하다.
airflow backfill -s start_date -e end_date dag_id통해 백필 가능- RUN(Execution Date)는 실제로 DagRun이 생성된 시간이다.
- Task Group을 이용해 Task를 묶을 수 있다.
- Event Driven Auto Scaler로 kubernetes에선 KEDA를 쓸 수 있다.
Reference
https://airflow.apache.org/
https://github.com/apache/airflow-on-k8s-operator
실시간 빅데이터 처리를 위한 Spark & Flink Online
https://www.bucketplace.co.kr/post/2021-04-13-%EB%B2%84%ED%82%B7%ED%94%8C%EB%A0%88%EC%9D%B4%EC%8A%A4-airflow-%EB%8F%84%EC%9E%85%EA%B8%B0/