Kafka 훑고 지나가기
Kafka Introduction
Kafka란?
Kafka는 대용량 분산 스트리밍 플랫폼으로, LinkedIn에 의해 만들어진 오픈소스이다. 언뜻보면 Messaging Queue와 비슷하지 않나 싶을 수 있지만, 기존 메세징 시스템과는 달리 메세지를 파일 시스템에 저장해 Durability를 보장한다. 카프카는 Messaging Queing Model과 Pub/Sub System의 특징을 둘다 가지고 있는데, consumer group이라는 개념을 통해 둘을 적절히 합쳤다. Kafka에 대해 기초적으로 설명하면, Source System은 Kafka로 메세지를 보내고, Destination System이 Kafka를 통해 받는다. 모든 시스템이 Kafka를 통해 통신하게 할 수 있기에, 시스템간 의존성을 간접적으로 만들어 복잡도를 줄일 수 있다. 카프카의 장점을 몇개 나열하자면 다음과 같다.
- Scalability: 하루에 1조개의 메세지가 처리 가능하고, Petabyte 단위의 데이터도 처리 가능하다.
- Low Latency/High Throughput: 메시지를 더 많이, 빠르게 전달할 수 있다.
- Availability: 클러스터 환경에서 작동하여 어떤 브로커가 망가지더라도 다른 브로커를 쓰면 된다.
- 데이터 저장 성능: 데이터가 분산 처리 되고, durability가 있으며(replication 기능으로 다른 node에 복사 가능), fault tolerant 하다
이러한 카프카는 시스템간 메세지 큐, 로그 수집, 스트림 프로세싱, 이벤트 드리븐한 기능들 등에 편하게 사용이 가능하다.
Kafka 구성
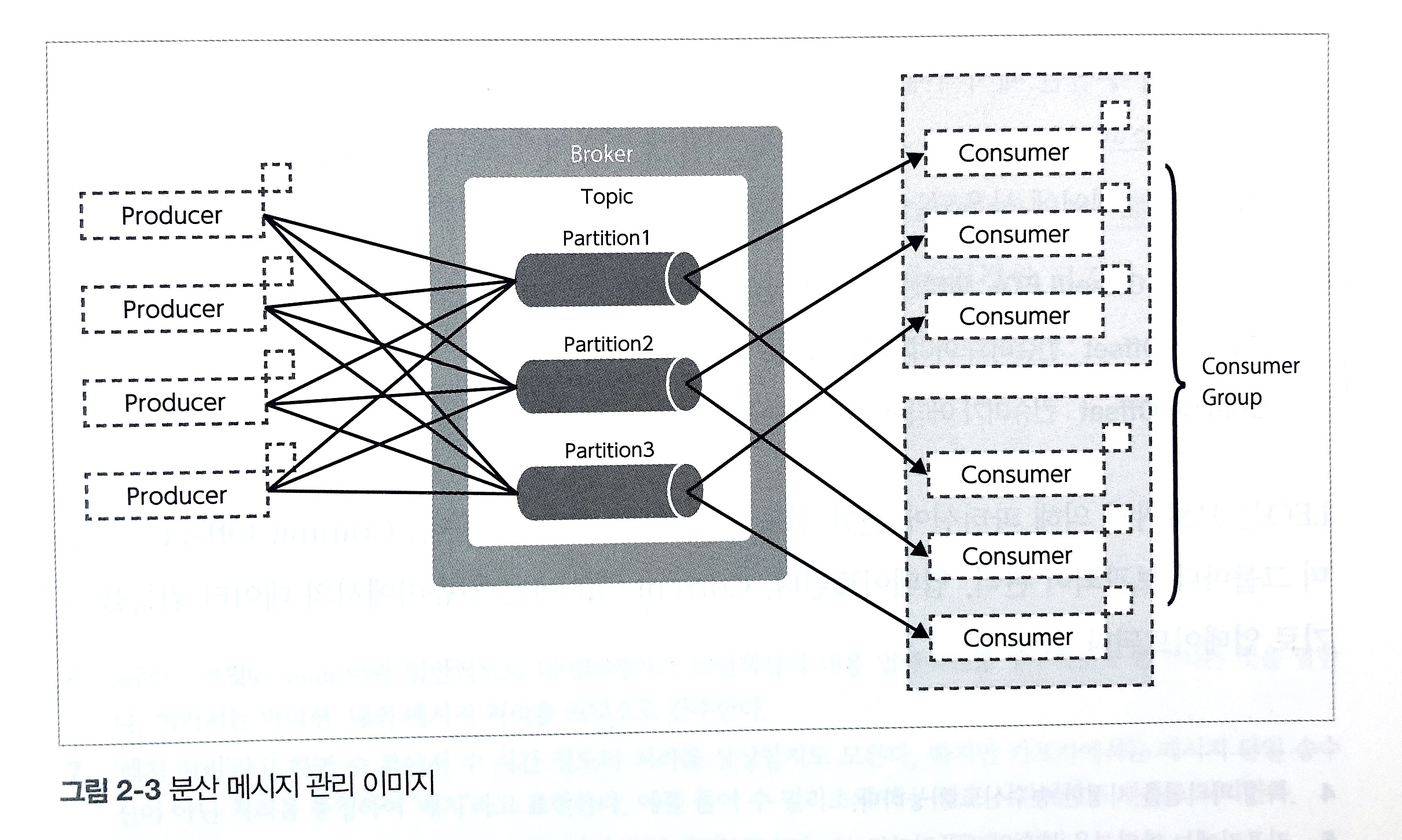
Kafka의 중요한 구성요소는 다음과 같다.
- Topic
Topic은 데이터 스트림이 어디 publish 되는지 지정해주는데, 하나의 채널/폴더라 보면 편하다. 프로듀서와 컨슈머가 소통하는 곳이다. - Broker
Server라고도 불리는데, Topic을 서빙하는 곳이다. - Producer
클라이언트 어플리케이션으로서 메세지를 Topic으로 보내는 곳이다. 메세지에 key를 지정하여 어느 파티션에 넣을지 결정할 수 있다. - Consumer
Topic으로부터 메세지를 받는 곳이다. - Partition
Topic을 나누는 구성 요소로, 실제 disk에 어떻게 저장되는지 가른다. 파티션에 들어온 순서에 따라 offset을 지정한다 (메세지를 식별하는 역할을 한다). 카프카의 메세지는 파티션 단위로 디스크에 정렬되어 저장이 되고, 세로운 메세지가 오면 지속적으로 각 로그에 기록이 된다. 이러한 로그는불변하고 delete되지 않는다. 카프카의 메세지는 byte의 배열로 string, JSON, Avro format을 지원한다. 또한, 데이터는 사용자가 지정한 Retention Period 길이 동안 저장이 된다. - Consumer Group
Consumer가 이루고 있는 Group이다. 따로 Consumer Group을 지정하지 않으면 하나의 Consumer를 위한 Consumer Group이 생긴다. 각 Consumer Group은 모든 파티션으로부터 데이터를 받아올 수 있다. 그러나 Consumer Group내 Consumer는 지정된 partition에서만 받아올 수 있다. Consumer Group에 Consumer 숫자에 변경이 일어나면 partition 배정에rebalancing이 일어나게 된다. - Cluster
그림에는 나와 있지 않지만 하나의 Topic에 대해서 여러개의 Broker를 사용할 수 있다. Producer가 메세지를 게시하면 Key가 있지 않는 경우Round-Robin방식으로 브로커내 토픽의 파티션들에 분배가 되는데, partition 1, partition 2, partition 3, .., partition n까지 동등하게 보낸다. key가 있다면 같은 key를 가진 메세지는 동일한 partition에 분배한다.Replication Factor가 있는 경우, 파티션이 Replication Factor만큼의 브로커에 가게 된다. Partition이 망가져도 온전히 서빙하기 위함이다. 이러한 경우 파티션 리더를 정하게 되는데, 파티션 리더를 통하여 Read/Write를 하게 되고 나머지 파티션들은 복제만 하고 장애가 났을때 리더만 바뀌게 된다. - Zookeeper
Kafka의 여러 요소의 설정을 코디네이터이다. 코디네이터로서 분산 시스템들 간의 정보를 공유하고, 상태를 체크하며 동기화를 진행한다.주키퍼 또한 클러스터(앙상블)로 구성되는데, 홀수로 구성되어 문제가 생겼을 경우 과반수의 데이터를 기준으로 일관성을 유지한다. 주키퍼가 하는 역할은클러스터 관리로 클러스터 내 브로커를 관리하고 모니터링하고,Topic 관리를 하여 topic list를 관리하고 해당 토픽별 파티션과 replication을 관리한다. 또한파티션 리더 관리를 하여 리더가 될 브로커를 정해주고 장애 시 대체까지 해준다. Zookeeper는 상태 정보를znode라 하는 곳에 key-value 형태로 저장한다. znode는 계층 형태를 띄고 있다.
Kafka 설치
카프카 공식 웹사이트에서 알맞는 스칼라 버전에 맞는 버전을 다운 받을 수 있다. 다운 받게 되면 압축된 파일을 받게 되는데, 이걸 풀어주면 된다. 이후 shell file과 properties들을 확인할 수 있는데, properties에 맞게 사용해주면 된다.
# Kafka 서버 시작하기
./bin/kafka-server-start.sh -daemon ./config/server.properties
# Kafka 토픽 만들기
./bin/kafka-topics.sh --create --bootstrap-server <server-address> --topic <topic-name> --partition <partition-number>--replication-factor <replication-number>
# Kafka 토픽 확인하기
./bin/kafka-topics.sh --describe --bootstrap-server <server-address>
# Kafka 토픽 확인하기
./bin/kafka-topics.sh --delete --bootstrap-server <server-address> --topic <topic-name>
# Producer 띄우기
./bin/kafka-console-producer.sh --bootstrap-server <server-address> --topic <topic-name>
# Consumer 띄우기
./bin/kafka-console-consumer.sh --bootstrap-server <server-address> --topic <topic-name> --group <consumer-group-name>
# Consumer Group 확인
./bin/kafka-consumer-groups.sh --bootstrap-server <server-address> --describe --group <consumer-group-name>
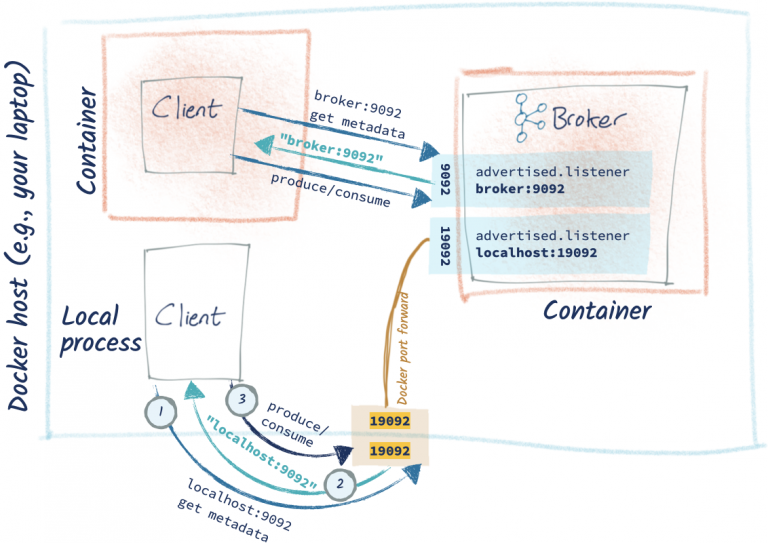
그러나 보통 kafka는 도커 환경에서 많이 사용하곤 한다. 구축하기에 앞서, 이 사진은 이해에 너무나도 큰 도움이 된다.
docker-compose.yaml은 다음과 같은 형태를 띄게 되는데,
version: '3'
services:
zookeeper:
image: zookeeper:3.7
hostname: zookeeper
ports:
- "2181:2181"
environment:
ZOO_MY_ID: 1
ZOO_PORT: 2181
volumes:
- ./data/zookeeper/data:/data
- ./data/zookeeper/datalog:/datalogco
kafka:
image: confluentinc/cp-kafka:7.0.0
hostname: kafka
ports:
- "9091:9091"
environment:
KAFKA_ADVERTISED_LISTENERS: LISTENER_DOCKER_INTERNAL://kafka1:19092,LISTENER_DOCKER_EXTERNAL://${DOCKER_HOST_IP:-127.0.0.1}:9092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: LISTENER_DOCKER_INTERNAL:PLAINTEXT,LISTENER_DOCKER_EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: LISTENER_DOCKER_INTERNAL
KAFKA_ZOOKEEPER_CONNECT: "zookeeper:2181"
KAFKA_BROKER_ID: 1
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
volumes:
- ./data/kafka/data:/tmp/kafka-logs
depends_on:
- zookeeper
여기서 좀 궁금해 할만한것 몇개를 설명하자면,
- Zookeeper 내 MY_ID는 주키퍼 노드별로 갖을 고유 번호이다.
- KAFKA_LISTNER는 다음과 같이
LISTENER_DOCKER_INTERNAL과LISTENER_DOCKER_EXTERNAL가 있다! 이게 무슨 뜻일까? 위에 그림에서 나와 있듯, 브로커는 도커안에서 Client와 통신을 해야하고, 도커 외부에서 클라이언트와 통신을 해야하는데 이 경우 포트가 다음과 같이 19092과 9092로 다르게 열어줘야 한다. LISTENER_DOCKER_EXTERNAL:PLAINTEXT는 뭐하는 뜻일까? 도커 밖의 producer/consumer가 내부에 접근하려하면 Kafka로 부터 LISTENER_DOCKER_EXTERNAL을 통해 연결하려하고, Kafka는 그렇다면 PLAINTEXT://LISTENER_DOCKER_EXTERNAL로 redirect한다. 그렇다면 producer/consumer는 이와 연결하고 메세지를 produce/consume하게 된다. PLAINTEXT는 리스너가 authenticate하지 않고 encryted되지 않겠다는 뜻이다.KAFKA_INTER_BROKER_LISTENER_NAME는 브로커간 통신에 활용할 리스너를 뜻한다. 이렇게 간단하게 브로커 하나와 주키퍼 하나로 구성한 카프카를 띄울 수 있다.
그렇다면 모니터링은 어떻게 할까? Kafdrop이나 KOWL을 쓰면 된다.
 KOWL을 많이들 쓰는거 같은데, 필자가 아는 정통한 Kafka 전문가 분에 따르면 ui도 이쁘고 관리툴로서의 기능도 어느정도 할 수 있어 사용한다고 한다.
KOWL을 많이들 쓰는거 같은데, 필자가 아는 정통한 Kafka 전문가 분에 따르면 ui도 이쁘고 관리툴로서의 기능도 어느정도 할 수 있어 사용한다고 한다.
Kafka Python에서 사용하기
Kafka를 Python에서 사용하기 위해서는 pip install kafka-python으로 다운받아 주어야 한다.
그 이후에는 다음과 같이 간단하게 producer와 consumer를 구축할 수 있다.
# producer 만들기
from kafka import KafkaProducer
broker = ['localhost:9092'] # broker가 여러개인 경우 여러개 넣어주기
producer = KafkaProducer(bootstrap_servers = [broker])
producer.send('first_topic', b'hi') # byte 메세지 보내는것을 추천, 토픽을 미리 만들자!
producer.flush() # flush로 완료
# consumer 만들기
from kafka import KafkaConsumer
broker = ['localhost:9092'] # broker가 여러개인 경우 여러개 넣어주기
consumer = KafkaProducer(bootstrap_servers = [broker]. topic = 'first-topic')
for message in consumer: # for loop은 무한루프
print(message.topic, message.partition, message.offset, message.key, message.value)
다음화에선 MSK에 대해서 조금 알아보고, 가능하면 Strimzi에 대해서도 알아보겠다.
Reference
실시간 빅데이터 처리를 위한 Spark & Flink Online
https://baek.dev/post/20/
https://www.confluent.io/ko-kr/blog/kafka-client-cannot-connect-to-broker-on-aws-on-docker-etc/
https://github.com/obsidiandynamics/kafdrop
https://github.com/cloudhut/kowl