쿠버네티스 없이 살 수 없는 몸이 되었다 (1)
Kubernetes World
이제 쿠버네티스는 MSA (Micro Service Architecture)를 위해 필수적인 플랫폼이 됐다.
MSA란 Micro Service Architecture로서 이전에 Monolithic한 방법과는 달리 각 컴포먼트를 서비스 형태로 따로 구현되고 API를 이용하여 서로 통신하게 된다. 이런 방법 덕분에 배포 단위도 작아지고, 변경에 대한 부담도 적으며, 서비스 별 최적의 기술을 사용할 수 있다. 쿠버네티스는 배포 스케줄링과 클라우드 환경을 지원해준다.
필자는 이러한 쿠버네티스를 마스터하기 위해 CKA 자격증을 따려고 준비중이긴 하다 (올해는 딴다…무조건!) 이러한 쿠버네티스의 기본 상식과 구조에 대해서 알아보자!
What is Kuberenetes
쿠버네티스는 컨테이너화된 서비스와 워크로드를 관리하기 위한 오픈소스 플랫폼이다. 쿠버네티스는 서비스 디스커버리와 로드 밸런싱, 자동화된 롤아웃과 롤백, Self-healing, 시크릿과 구성 관리 등 분산 시스템을 탄력적으로 실행하게 해준다.
Kubernetes 개념
쿠버네티스는 상태를 관리하기 위한 대상을 object라 한다 (이러한 Object는 영속성을 가지고 있다). 이러한 Object는 어떤 application이 구동중인지, 리소스는 얼만큼 제공되었는지, 어떤 policy를 가지고 있는지 기술할 수 있다. Object는 .yaml 파일을 통해 기술할 수 있으며, kubectl apply를 통해 적용할 수 있다. Kubernetes의 대표적인 Object는 Pod이다. Pod는 쿠버네티스에서 배포할 수 있는 가장 작은 단위로 한 개 이상의 컨테이너와 스토리지, 네트워크 속성을 가진다. 여러 컨테이너가 올라와 있다면 스토리와 컨테이너를 공유하며, localhost를 통하여 통신할 수 있다.
Kubernetes 구조
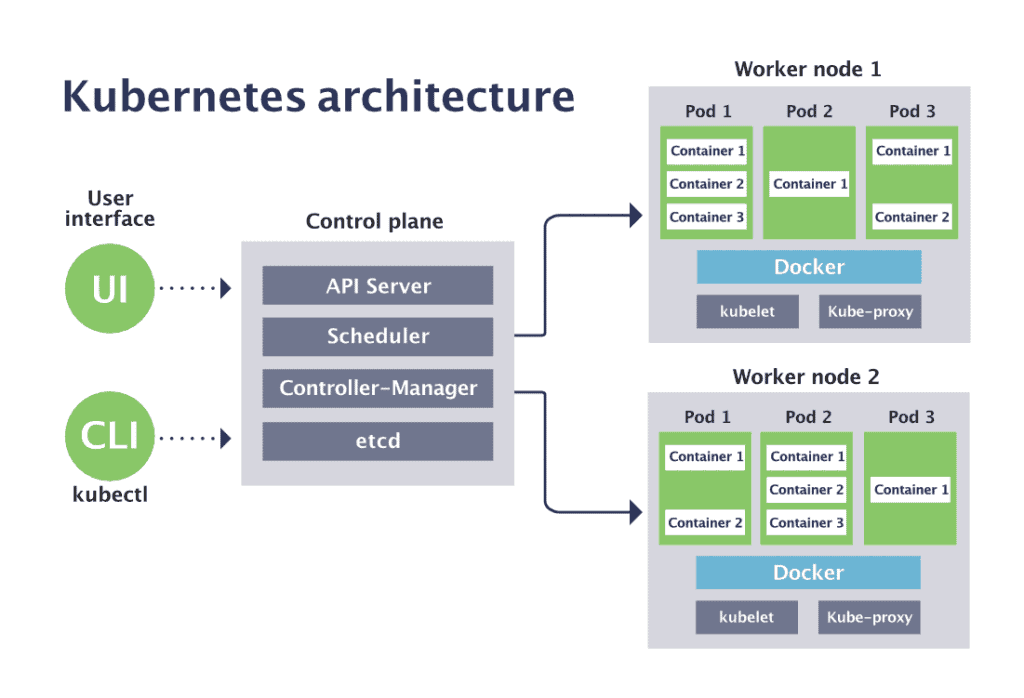
쿠버네티스는 기본적으로 Master (Control Plane)과 여러개의 Worker Node로 이루어져있다. 각 Master와 Worker Node에 대해 빠르게 알아보자.
Master 노드는 클러스터를 관리하는 친구들이며 관리자만 접속할 수 있게 보안 설정을 해야하고, 보통 고가용성을 위해 3대를 구성하는 편이다. EKS 같은 경우에는 AWS에서 직접 이걸 관리해준다. Master노드에는 다음과 같은 Component들이 있다.
API Server (kube-apiserver)
Kubectl과 UI에서 들어오는 모든 요청을 처리하는 역할을 한다. 원하는 상태를 etcd에 저장하고 상태를 조회하는 역할을 한다.etcd
RAFT 알고리즘을 이용한 key-value storage이다 (Leader election과 log replication을 하는 합의 알고리즘으로 서버중 일부가 장애가 발생하더라도 제 기능을 유지하게 한다). 여러 개로 분산하여 복제할 수 있다. 클러스터의 설정, 상태 데이터는 여기 모두 저장이 되어있다.scheudlerandcontroller
실제로 상태를 바꾸는 친구들이 바로 이 친구들이다. 스케줄러는 할당되지 않은 pod를 자원과 라벨에 따라 적절한 노드 서버에 할당해주는 역할을 한다. 컨트롤러 (kube-controller-manager)는 거의 모든 오브젝트의 상태를 관리하며 전체 시스템이 desired state로 유지 될 수 있게해준다.
Worker Node는 마스터와 통신하며 필요한 Pod를 생성하고 컨테이너를 만드는 역할을 한다. Node에는 다음과 같은 component가 있다.
kubelet
노드에 할당 된 pod의 life cycle을 관리한다. pod를 생성한뒤 pod안의 컨테이너에 이상여부를 확인한 뒤 마스터에 상태를 전달한다.kubeproxy
kubeproxy는 pod로 연결된 네트워크를 관리한다. TCP/UDP 스트림을 포워딩하고 서비스를 제공한다.
명령어는 kubectl을 통해 전달 할 수 있다. (Kubectl은 명령행 cli 도구 이다!) 그렇다면 pod는 어떻게 생성되게 될까?
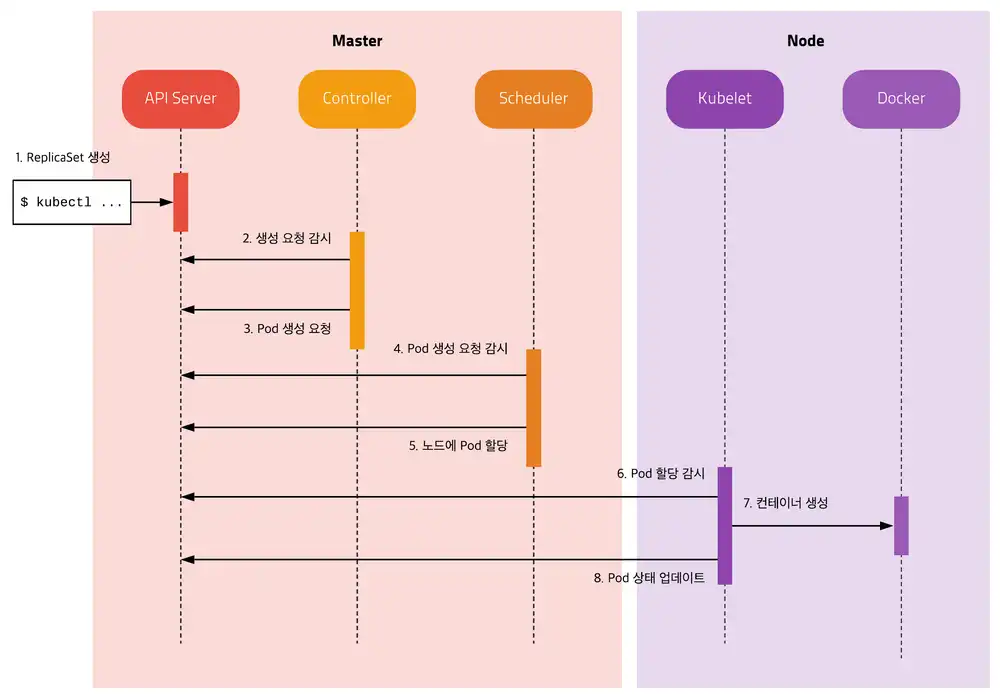
다음과 같이 replicaset을 생성하기 위한 명령어가 들어왔다 가정하자.
- 먼저 Kubectl에서 replicaset을 생성하기 위한 yaml을 받고 API server에 전달한다.
- API server는 replica set object를 etcd에 저장한다.
- kube controller는 생성요청을 감시하고 있다가 replicaset에서 정의된 label selector의 pod가 있는지 확인. 없으면 template을 보고 새 pod를 생성한다. 생성요청은 api server에 요청하고, API server는 etcd에 저장한다.
- 스케줄러는 마찬가지로 pod 생성 요청을 감시하다가, 할당되지않은 pod가 있다면 조건에 맞는 node에 찾아 할당한다.
- kubelet은 Node에 할당되었지만 생성되지않은 pod를 감시하고, pod를 생성한다. 주기적으로 상태를 API server에 보고한다.
이렇게 비교적 간단(?)하게 pod의 생성 과정을 알 수 있다.
Kubernetes 설치
EKS를 본인은 사용했었다. EKS로 이미 구성이 완료된 경우에는 다음과 같이 kubeconfig에 자격증명을 하고 kubectl을 사용할 수 있다. EKS로 사용하지 않으면 minikube나 k3s를 사용해도 되는 걸로 알고 있다.
다음번에는 kubectl의 기본적인 사용처와 여러 kind (deployment, service 등)을 정리해보도록 하겠다.
Reference
https://subicura.com/2019/05/19/kubernetes-basic-1.html
https://www.cncf.io/blog/2019/08/19/how-kubernetes-works/
https://subicura.com/k8s/